👉 [알고리즘] You Only Look Once (YOLO) 욜로 이해
You Only Look Once: Unified, Real-Time Object Detection
Joseph Redmon, Santosh Divvala, Ross Girshick, Ali Farhadi
(Submitted on 8 Jun 2015 (v1), last revised 9 May 2016 (this version, v5))
위 논문 내용에 대한 이해 및 서치를 바탕으로 개인적인 정리 내용입니다. 가끔 잘못 이해한 내용이 있을 수도.
기존의 컴퓨터 비젼 분야의 객체 인식 (Image Detection) 은 두 가지 단계를 거쳤다.
YOLO 이전에 주류 객체 인식 알고리즘인 R-CNN 을 예시로 들어보자.
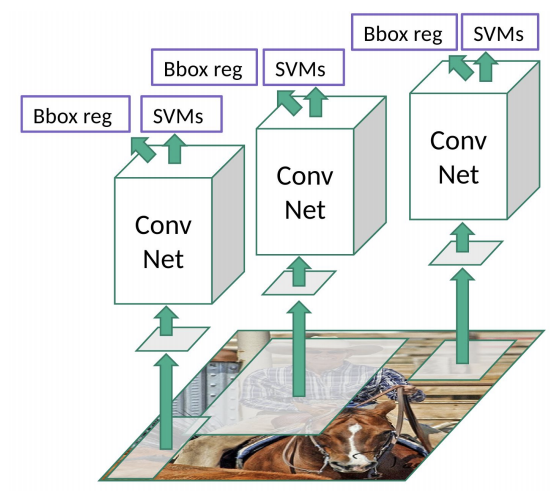
이미지 내의 특정 영역을 먼저 캐치한 후 (Region Proposal), 이에 대한 분류(Classification)를 진행하는 것이다.
순서대로 어떻게 대략적으로 진행하는지 알아보자.
1. Region Proposal
- 관심 영역을 제안하는 것으로, 이미지 내의 특정 구역에 객체가 존재할 가능성을 판단하고 이를 제안하는 과정이다. R-CNN 에서는 Selective Search 라는 알고리즘을 이용하여 제안하는데, (이 알고리즘도 꽤 재밌으니 나중에 차차 아라보자) 위 이미지에서 말에 탄 사람을 투명한 사각형을 지정한 것을 볼 수 있다. Region Proposal 을 시각화 한 것이다. 이런식으로 이미지 내의 객체가 존재할만한 부분들을 모아다가 분류하는 것이다.
2. Convolutional Neural Network
- 1번에서 제안된 영역을 잘 맞게 warping 하여, CNN 에 넣어 특징 맵(Image Featrue Map)을 생성한다!
3. Classification
- 2번에서 생성된 특징 맵을 분류기에 넣어 관심 영역이 어떤 객체인지 판별한다. SVM 분류기를 써서 했다카더라.
다른 이미지로 위 과정을 표현하면 아래와 같다.

물론 총 3가지 단계로 분류가 되었지만, 자세히 분류했기 때문이고. 실질적으로는 가장 중요한 2가지 단계로 나뉜다.
Region Proposal 과 Classification 이다. 이미지 내에 어느 곳에 존재하며, 무엇이 존재하는지를 판별하는 것이 객체 인식의 주된 내용이기 때문이다.
* CNN 파트는 아마 그냥 특징 추출 정도의 단순한 과정이기에 Two Stage 라고 불리우는거 아닐까 싶기도 하다. CNN 말고 Haar Feature, HOG Feature 등으로도 할 수는 있으니까 말이다.
아무튼 위와 같은 방식으로 진행되던 객체 인식은 큰 단점이 있었는데, 2000개나 되는 Region Proposal에 대해 각각 돌리므로 상당히 비용이 컸다고 한다. 1 프레임 정도 밖에 안나왔다는데, 요즘 대세는 Real Time이 아니던가. 따라서 실시간으로 구현되는 인식기를 만들고 싶었던 저자가 YOLO 라는 핵폭탄을 탄생시켰다. 무려 YOLO는 45 프레임이다. Small 버젼은 155 라고 한다.
이제 그래서 YOLO 가 뭔지 알아보자.

YOLO 저자들은 이 Two Stage를 Unified Dection 이라는 개념으로 한번에 진행하였다. 즉 어느 곳에 존재하는지 와 무엇이 존재하는지 를 한번에 프로세싱하는 방법을 구현한 것이다.
YOLO is refreshingly simple: see Figure 1. A single convolutional network simultaneously predicts multiple bounding boxes and class probabilities for those boxes. YOLO trains on full images and directly optimizes detection performance. This unified model has several benefits over traditional methods of object detection.
> 욜로는 열라 단순: 하나짜리 CNN이 여러 바운딩 박스들과 이에 대한 클래스 분류 확률(어떤 클래스인지 가능성에 대한 확률)까지 동시에 예측한다!
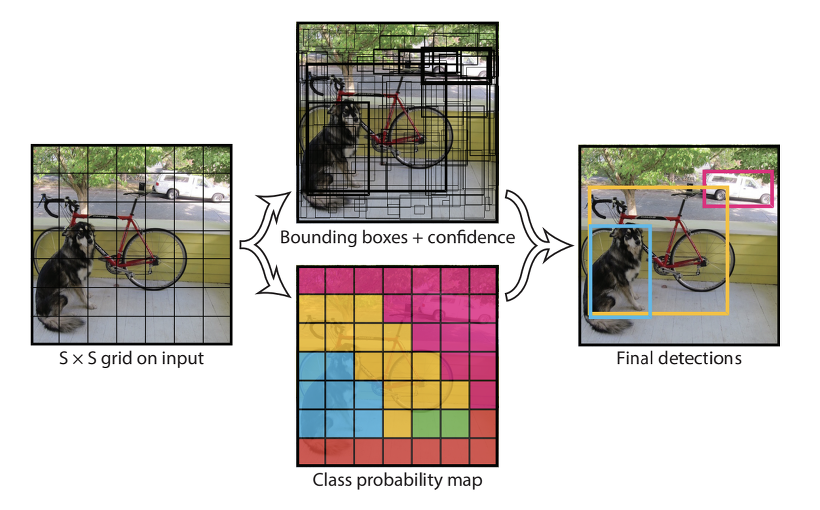
1. S x S 의 정사각형으로 입력 이미지를 나눈다.
2. 바운딩 박스, 박스 당 컨피던스 값 , 클래스 분류 확률을 구한다.
* 박스 당 컨피던스 값 : 해당 박스가 객체를 포함할 가능성
* 클래스 분류 확률 : 탐지된 클래스가 어느 클래스에 해당하는지 나타낼 확률
3. 임계값 이상의 박스만 표기한다.

사실 YOLO가 중요한 이유는 앞서 언급했듯이, Real-Time 이기 때문에, 아래 영상을 보면 답이 나온다.
https://youtu.be/Cgxsv1riJhI?t=157
TED 강연으로, YOLO 데모를 이전 알고리즘과 비교해준다. (2:37)